Industri kecerdasan buatan global kembali dikejutkan dengan peluncuran pratinjau DeepSeek V4 pada 24 April 2026. Seri terbaru ini hadir bukan sekadar sebagai pembaruan rutin, melainkan sebuah lompatan besar dalam arsitektur AI yang dirancang untuk mendobrak hambatan efisiensi pada pemrosesan konteks ultra-panjang.
Melalui pendekatan Mixture-of-Experts (MoE) yang disempurnakan, DeepSeek memperkenalkan dua model unggulan: DeepSeek-V4-Pro dengan 1,6 triliun parameter dan versi yang lebih efisien, DeepSeek-V4-Flash.
Keduanya membawa kemampuan revolusioner dalam menangani jendela konteks hingga satu juta token, memungkinkan tim untuk memproses ribuan dokumen atau basis kode yang sangat besar secara sekaligus tanpa kehilangan detail.
Lebih dari sekadar angka performa, DeepSeek V4 juga menandai babak baru kedaulatan teknologi melalui integrasi yang mulus dengan perangkat keras domestik seperti NPU Ascend Huawei, yang secara efektif mengurangi ketergantungan industri pada ekosistem GPU Nvidia.
Dengan ketersediaan open weights dan akses API yang kompatibel, DeepSeek V4 siap menjadi fondasi baru bagi para pengembang dan perusahaan yang mengutamakan kualitas penalaran tinggi dengan efisiensi biaya yang luar biasa.
Mari kita bedah lebih dalam bagaimana inovasi ini bekerja dan mengapa ini menjadi standar baru bagi model AI masa depan.
Baca Juga: Analisis Naratif: Pengertian, Jenis, & 5 Langkah Melakukannya
Dua Varian Unggulan: DeepSeek-V4-Pro dan DeepSeek-V4-Flash

Seperti generasi sebelumnya, seri V4 mempertahankan kerangka kerja Mixture-of-Experts (MoE) dan strategi Multi-Token Prediction (MTP), namun dengan optimasi yang jauh lebih matang.
Untuk mengakomodasi berbagai kebutuhan mulai dari riset kelas berat hingga otomatisasi layanan pelanggan berkecepatan tinggi—DeepSeek merilis model ini dalam dua varian utama, yakni versi Pro dan Flash.
Berikut adalah spesifikasi dari kedua varian tersebut:
1. DeepSeek-V4-Pro: Tenaga Penuh untuk Tugas Kompleks
Diposisikan sebagai model flagship, varian Pro dirancang khusus untuk menangani penalaran tingkat lanjut, pemrograman yang rumit, serta tugas berbasis agentic AI yang membutuhkan pengambilan keputusan multi-langkah.
- Total Parameter: Memiliki skala masif sebesar 1,6 triliun parameter.
- Parameter Aktif: Hanya 49 miliar parameter yang diaktifkan (activated) untuk setiap pemrosesan token, sehingga tetap menjaga kecepatan meski ukurannya raksasa.
- Arsitektur: Menggunakan 61 lapisan Transformer dengan dimensi tersembunyi (hidden dimension) sebesar 7168.
- Ideal untuk: Penelitian ilmiah, pengembangan software, analisis strategis enterprise, dan penyelesaian masalah matematika tingkat kompetisi Olimpiade.
2. DeepSeek-V4-Flash: Ramping, Cepat, dan Hemat Biaya
Bagi pengembang yang membutuhkan latensi super rendah dan biaya operasional (cost-efficiency) yang hemat tanpa mengorbankan panjang konteks, varian Flash adalah jawabannya.
- Total Parameter: Jauh lebih ringkas dengan 284 miliar parameter.
- Parameter Aktif: Sangat efisien, dengan hanya 13 miliar parameter aktif per token.
- Arsitektur: Terdiri dari 43 lapisan Transformer dengan dimensi tersembunyi sebesar 4096.
- Ideal untuk: Aplikasi yang melayani banyak pengguna secara instan (high-throughput), chatbot sehari-hari, ekstraksi dokumen, dan tugas-tugas administratif rutin.
Kedua varian ini sama-sama telah melewati proses pre-training yang intensif menggunakan kumpulan data berkualitas tinggi. DeepSeek-V4-Flash dilatih menggunakan lebih dari 32 triliun token, sementara versi Pro dilatih pada 33 triliun token. Hasilnya, baik model Pro maupun Flash memiliki dukungan native yang kuat untuk menganalisis konteks hingga 1 juta token secara efisien sejak peluncuran perdananya.
Tiga Inovasi Arsitektur Utama di Balik DeepSeek V4
Untuk mencapai efisiensi ekstrem pada jendela konteks satu juta token, DeepSeek V4 tidak hanya mengandalkan penambahan hardware, melainkan melakukan perombakan besar pada struktur internal modelnya. Terdapat tiga teknologi kunci yang menjadi tulang punggung kecerdasan V4:
1. Hybrid Attention (CSA & HCA)
Komponen attention biasanya menjadi hambatan utama dalam memproses teks panjang karena kebutuhan memori yang membengkak. DeepSeek V4 memecahkan masalah ini dengan menggabungkan dua metode kompresi:
- Compressed Sparse Attention (CSA): Metode ini mengompresi setiap $m$ token menjadi satu entri Key-Value (KV) dan menerapkan DeepSeek Sparse Attention (DSA), di mana setiap token hanya memperhatikan entri tertentu yang paling relevan.
- Heavily Compressed Attention (HCA): Digunakan untuk kompresi yang lebih agresif ($m’ \gg m$) namun tetap mempertahankan mekanisme dense attention.
- Hasil: Kombinasi ini secara dramatis mengurangi beban komputasi dan ukuran KV cache pada skenario ultra-panjang.
2. Manifold-Constrained Hyper-Connections (mHC)
DeepSeek V4 memperkenalkan mHC untuk memperkuat koneksi residual konvensional yang ada pada arsitektur Transformer.
- Stabilitas Sinyal: Teknologi ini membatasi pemetaan residual pada manifold tertentu (matriks doubly stochastic) untuk meningkatkan stabilitas perambatan sinyal di seluruh lapisan model.
- Ekspresivitas Model: Dengan mHC, model tetap memiliki kemampuan ekspresi yang tinggi tanpa risiko ketidakstabilan numerik saat dilatih dalam skala triliunan parameter.
3. Muon Optimizer
Dibandingkan menggunakan optimizer standar seperti AdamW untuk seluruh bagian, DeepSeek V4 beralih ke optimizer Muon untuk mayoritas modulnya.
- Konvergensi Cepat: Muon dirancang untuk memberikan konvergensi yang lebih cepat, artinya model mencapai tingkat kecerdasan tertentu dalam waktu pelatihan yang lebih singkat.
- Ortogonalisasi: Optimizer ini menggunakan iterasi hybrid Newton-Schulz untuk memastikan pembaruan parameter tetap efisien dan stabil selama proses pembelajaran.
- Efisiensi Pelatihan: Penggunaan Muon berkontribusi signifikan pada penghematan sumber daya komputasi sekaligus meningkatkan performa akhir model.
Efisiensi Komputasi dan Pemrosesan Konteks Panjang
Salah satu pencapaian paling menonjol dari DeepSeek V4 adalah kemampuannya untuk tetap bekerja dengan sangat efisien meskipun sedang menangani data dalam jumlah raksasa.
Melalui inovasi arsitektur yang cerdas, model ini berhasil mendobrak batasan memori yang biasanya menjadi kendala utama pada model AI generasi sebelumnya.
Lompatan Efisiensi Dibandingkan DeepSeek-V3.2
Angka efisiensi yang ditawarkan oleh seri V4 sangat signifikan, terutama saat bekerja dalam skenario jendela konteks hingga 1 juta token:
- DeepSeek-V4-Pro: Hanya membutuhkan 27% FLOPs (beban komputasi) inferensi token tunggal dibandingkan dengan pendahulunya, DeepSeek-V3.2.
- Penghematan Memori Pro: Penggunaan KV cache pada varian Pro menyusut drastis hingga hanya 10% dari ruang yang dibutuhkan oleh generasi sebelumnya pada panjang konteks yang sama.
- Efisiensi Varian Flash: DeepSeek-V4-Flash bahkan melangkah lebih jauh dengan hanya memerlukan 10% FLOPs dan 7% KV cache dibandingkan DeepSeek-V3.2.
- Operasional Praktis: Penghematan ini membuat tugas-tugas jangka panjang dan analisis dokumen lintas-dokumen yang masif menjadi jauh lebih layak untuk dijalankan secara rutin.
Skala Data Pelatihan yang Masif
Kecerdasan DeepSeek V4 didukung oleh fondasi data yang sangat luas dan telah dikurasi secara ketat:
- Volume Data: Secara keseluruhan, model-model ini dilatih menggunakan lebih dari 32 triliun token yang sangat beragam dan berkualitas tinggi.
- Pelatihan Varian Flash: Varian DeepSeek-V4-Flash secara spesifik dilatih menggunakan 32 triliun token.
- Pelatihan Varian Pro: Varian DeepSeek-V4-Pro dilatih pada korpus data yang sedikit lebih besar, mencapai 33 triliun token.
- Kualitas dan Diversitas: Kumpulan data ini mencakup konten matematika, kode pemrograman, dokumen teknis, hingga makalah ilmiah untuk memastikan model memiliki pemahaman dunia yang mendalam.
Mengapa Konteks 1 Juta Token Begitu Penting?
Dukungan asli untuk satu juta token bukan sekadar angka di atas kertas, melainkan pembuka gerbang bagi kapabilitas baru:
- Analisis Dokumen Raksasa: Tim dapat memasukkan seluruh dokumentasi teknis atau strategi bisnis jangka panjang ke dalam satu sesi analisis tanpa terpotong.
- Kontinuitas Proyek: Memungkinkan pemeliharaan konteks yang berkelanjutan selama berminggu-minggu perencanaan proyek tanpa perlu melakukan pengulangan informasi.
- Fondasi Belajar Mandiri: Efisiensi dalam menangani urutan ultra-panjang ini menjadi fondasi penting bagi eksplorasi masa depan seperti pembelajaran daring (online learning).
Performa State-of-the-Art di Kelas Open-Source
Kehadiran DeepSeek V4 bukan hanya tentang efisiensi, tetapi juga tentang pembuktian bahwa model terbuka (open models) kini mampu bersaing di level tertinggi dengan model tertutup (proprietary) milik raksasa teknologi dunia. Melalui varian tertingginya, DeepSeek V4 telah mencetak standar baru dalam ekosistem AI.
DeepSeek-V4-Pro-Max: Sang Juara Baru Model Terbuka
Mode DeepSeek-V4-Pro-Max, yang merupakan konfigurasi dengan upaya penalaran maksimal dari varian Pro, berhasil mendefinisikan ulang standar tertinggi (state-of-the-art) untuk model sumber terbuka.
- Melampaui Pendahulu: Model ini secara signifikan mengungguli model-model DeepSeek generasi sebelumnya di berbagai tugas inti.
- Dominasi Terbuka: Performa puncaknya tercatat melampaui model terbuka terkemuka lainnya seperti Kimi-K2.6 dan GLM-5.1 dalam berbagai pengujian internal.
- Menipiskan Jarak: DeepSeek-V4-Pro-Max berhasil memperpendek jarak secara drastis dengan model tertutup papan atas seperti Gemini-3.1-Pro dan GPT-5.4.
Dominasi di Berbagai Bidang Utama
Kemampuan DeepSeek V4 tersebar merata di berbagai domain kritis yang menjadi tolok ukur kecerdasan AI modern:
1. Pengetahuan Dunia (World Knowledge)
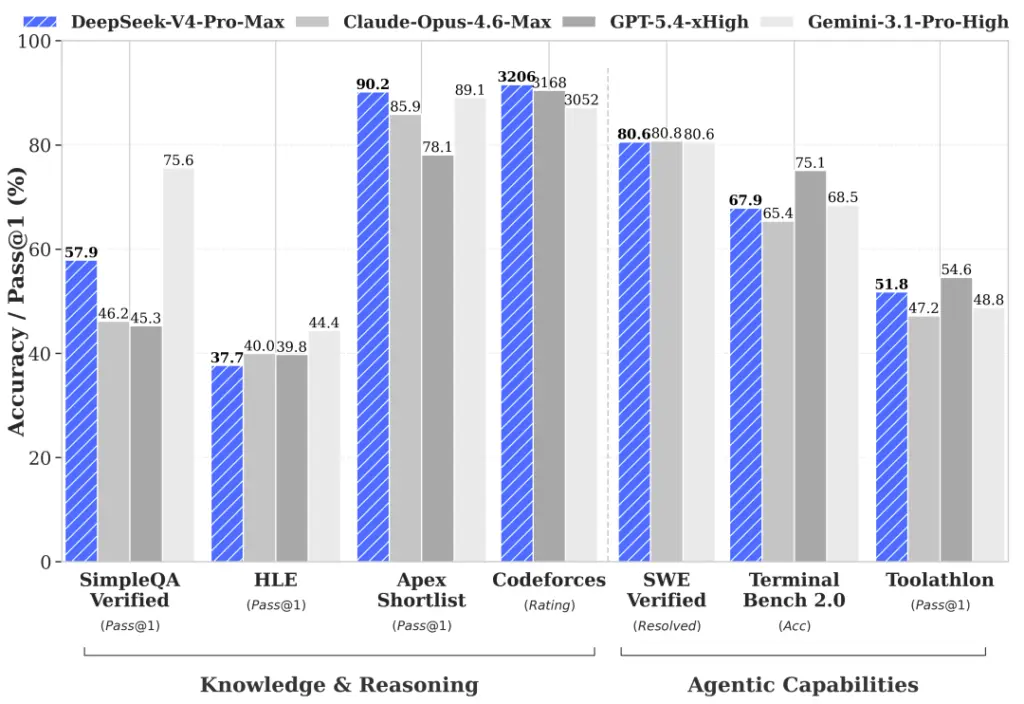
- Dalam benchmark SimpleQA-Verified, DeepSeek-V4-Pro-Max mengungguli semua model open-source lainnya dengan selisih hingga 20 poin persentase.
- Model ini juga menunjukkan kepemimpinan pada tolok ukur pengetahuan edukasi seperti MMLU-Pro, HLE, dan GPQA.
2. Penalaran dan Matematika (Reasoning)
- Melalui ekspansi token penalaran, model ini mendemonstrasikan performa yang lebih unggul dibandingkan GPT-5.2 dan Gemini-3.0-Pro pada benchmark penalaran standar.
- Dalam tugas matematika formal, DeepSeek V4 mencapai hasil sempurna (120/120) pada evaluasi Putnam-2025 menggunakan rezim penalaran hibrida formal-informal.
3. Pengkodean (Coding)
- DeepSeek V4 menunjukkan performa yang setara dengan GPT-5.4 dalam kompetisi pemrograman.
- Pada papan peringkat Codeforces, DeepSeek-V4-Pro-Max saat ini menempati peringkat ke-23 di antara kandidat manusia, membuktikan kemampuannya dalam menyelesaikan masalah logika pemrograman yang sangat kompleks.
4. Kapabilitas Agen AI (Agentic Capabilities)
- Dalam evaluasi agen pengkodean R&D internal, DeepSeek-V4-Pro mengungguli Claude Sonnet 4.5 dan mendekati level Claude Opus 4.5.
- Model ini menunjukkan kemampuan generalisasi yang luar biasa pada platform seperti MCPAtlas dan Toolathlon, membuktikan bahwa ia tidak hanya unggul di lingkungan internal tetapi juga pada berbagai alat dan layanan pihak ketiga.
Kesimpulan: DeepSeek V4 dan Masa Depan AI Tanpa Batas
Peluncuran DeepSeek V4 bukan sekadar pembaruan rutin, melainkan sebuah tonggak sejarah yang mendefinisikan ulang batas efisiensi dalam dunia model bahasa besar. Melalui arsitektur hibrida yang revolusioner, model ini membuktikan bahwa jendela konteks hingga satu juta token kini dapat dikelola dengan biaya komputasi yang jauh lebih rendah dibandingkan generasi sebelumnya.
Beberapa poin utama yang dapat kita bawa dari kehadiran DeepSeek V4 adalah:
- Standar Baru Model Terbuka: DeepSeek-V4-Pro-Max telah menetapkan standar state-of-the-art baru, membuktikan bahwa model open-source mampu bersaing langsung dengan model tertutup paling canggih di dunia.
- Efisiensi sebagai Prioritas: Penghematan FLOPs dan penggunaan KV cache yang signifikan memungkinkan perusahaan menjalankan tugas-tugas kompleks dengan biaya yang jauh lebih terjangkau.
- Kemandirian Infrastruktur: Keberhasilan adaptasi pada NPU Ascend Huawei menandai langkah besar menuju ekosistem AI yang mandiri dan tidak lagi bergantung sepenuhnya pada satu jenis perangkat keras global.
- Potensi Masa Depan: Dengan efisiensi ultra-panjang ini, DeepSeek telah meletakkan fondasi kuat untuk pengembangan tugas agen AI yang lebih rumit, test-time scaling, hingga paradigma online learning.
Hadirnya DeepSeek V4 dalam versi pratinjau ini mengundang para pengembang dan pemimpin bisnis untuk mulai mengeksplorasi bagaimana AI dengan konteks “tak terbatas” dapat mentransformasi alur kerja mereka. Masa depan AI yang lebih terbuka, fleksibel, dan terjangkau kini sudah ada di depan mata.
Buat kamu penulis agar proses menulismu jauh lebih cepat dan efisien, kamu bisa menggunakan nuliskata. Platform AI writing tools lengkap ini menyediakan fitur parafrase online, summarizer, translator, humanizer, dan AI writer dalam satu tempat.
Tingkatkan produktivitas menulismu sekarang bersama nuliskata dan selesaikan laporan penelitianmu dengan hasil yang lebih berkualitas dan profesional!